



用“AI+区块链”织成工业设备安全网
 2026-06-03
2026-06-03
 290
290

现代工业和商业楼宇中,大型中央空调的“水冷磁悬浮冷水机组”是维持整体运转的核心设备。一旦这些巨型设备突发故障,不仅会降低用户的体验,还可能给企业带来不小的经济损失。因此,如何利用人工智能(AI)提前预测并检测设备故障,成了工业物联网(IIoT)领域的重要课题 。
传统的故障检测方法存在一个痛点:各家合作单位(比如各大酒店)需要将设备的原始运行数据统一上传到厂家的中央服务器进行集中训练。这些数据往往包含着敏感的商业机密,例如通过空调的使用频率和时间,就能轻易推算出酒店的实际入住率。由于担心隐私泄露,很多单位并不愿意共享数据,导致AI模型因缺乏足够的数据支持进行高效训练。这篇设计了一套基于区块链的联邦学习平台架构,让多方设备在“数据不出门”的前提下协同训练,并用精妙的数学机制克服了数据不均匀的难题。
为了保护隐私,这套系统采用了联邦学习(Federated Learning)技术。各大酒店的服务器只需要在本地利用自己的空调数据训练AI模型,将更新后的“模型参数(权重)”发送给中央服务器进行聚合,原始数据自始至终保留在本地。
然而,常规的联学习算法(如谷歌的FedAvg)中,因为每个地点的空调工作环境(如天气)和使用人群(如年龄)各不相同,导致每家单位收集到的数据分布有着强烈的异质性(不均匀性)。为了解决这个问题,研究团队开创性地提出了“质心距离权重联邦平均(CDW_FedAvg)”算法。这个算法会观察每个单位数据集中“正常运行数据”与“故障数据”之间的几何距离 。

Fig. 7展示了经过降维处理后的4个不同合作单位(Client #1到#4)的数据分布散点图 。图中蓝色的点代表正常运行(Normal),红色的点代表出现故障(Abnormal)。可以直观地看到,Dataset #3(第三个单位)的红色点和蓝色点之间有着非常明显的空间距离,而其他几个单位的红蓝散点分布更为集中、分界不明显。研究团队的算法正是通过计算这两个数据“质心”之间的距离,旨在动态调整各方在全局大模型融合中的发言权,有效提升最终的诊断准确率 。
如果某个空调真的坏了,厂家和酒店之间对故障原因和损失责任产生争执该怎么办?系统引入了区块链(Blockchain)技术作为底层的信任根基。
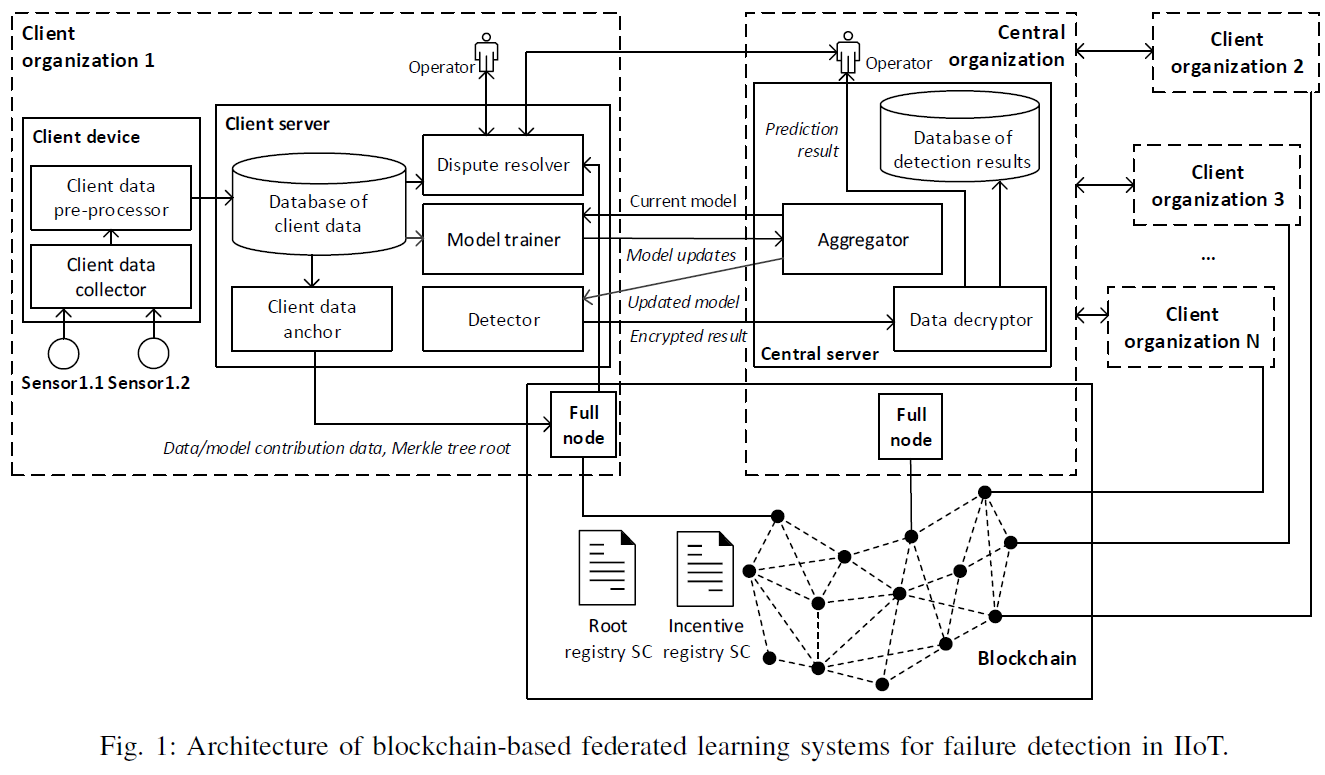

Fig. 1 展示了平台的完整架构,主要由左侧的“客户端组织(Client organization)”、右侧的“中央组织(Central organization)”以及下方的“区块链网络”共同构成 。结合Fig. 3的工作流,空调传感器采集到的数据会存入本地数据库。为了不让区块链因存储巨额工业数据而瘫痪,系统设计了一个锚定协议(Anchoring Protocol):本地服务器定期将这些海量数据通过哈希运算织成一棵 “默克尔树(Merkle Tree)”,然后只把这棵树的树根(相当于数据总指纹)和时间戳发布到区块链的智能合约上。一旦发生纠纷,双方只需调出本地历史数据重新运算并与链上树根比对,就能验证数据是否被篡改过。
为了吸引更多的单位自愿加入到这个故障检测网络中来,平台还内置了一套基于智能合约的激励机制。只要某个单位的服务器完成了本地训练并上传了合格的更新参数,链上的智能合约(Incentive Registry SC)就会根据其贡献的数据大小(dataSize)以及质心距离(distance),自动计算并分发代币(Tokens)奖励。这些代币未来可以向厂家购买新的产品或升级维护服务。

Fig. 6展示了4个参与测试的客户端最终获得的代币数量柱状图。可以看到,Client #3(第三个单位)获得的蓝色柱子明显比其他三个单位高出一截。正是因为它的数据特征表现最好(红蓝分类距离最远),智能合约自动给予了它更高的收益权重,以此鼓励各方提供更多高质量、高清晰度的实体训练数据 。
这项研究的最后,团队在由阿里云服务器和树莓派微型电脑组成的实际工业原型机上进行了多轮测试。结果表明,这套“AI+区块链”的故障检测系统不仅在逻辑和功能上完全可行,而且其检测准确率与传统集中式模型不相上下。更重要的是,相比于集中上传动辄几个GB的原始工业数据,联邦学习每轮只需要传输144字节的模型更新参数,在保证商业隐私安全的同时,极大地节省了宝贵的网络带宽。
作者简介:张卫山,中国石油大学(华东)计算机科学与技术学院教授、博士生导师,人工智能系系主任。长期从事联邦学习、区块链、可信人工智能与大数据智能处理研究。
ORCID:0000-0001-9800-1068
DOI:10.1109/JIOT.2020.3032544











