



如何利用长短期记忆网络监测工业设备状态
 2026-06-03
2026-06-03
 1119
1119

现代化的发电厂中,各类大型工业设备的稳定运转是保障电力持续供应的基石。为了实时掌握这些机器的健康状况,工程人员通常会在设备上安装大量的传感器,用来收集温度、压力、振动等各类时间序列数据。如何从这些海量且充满噪点的数据中准确预测设备的运行状态,一直是工业物联网领域的一个技术难点。
这篇论文提出了一种基于长短期记忆(LSTM)深度神经网络的预测方法,并利用发电厂核心水泵的真实监测数据进行实证检验。
发电厂的设备结构异常复杂,传统的监测和分析方法在面对现代工业物联网的海量数据往往显得力不从心。论文通过一个具体的应用场景展示了数据的复杂性:
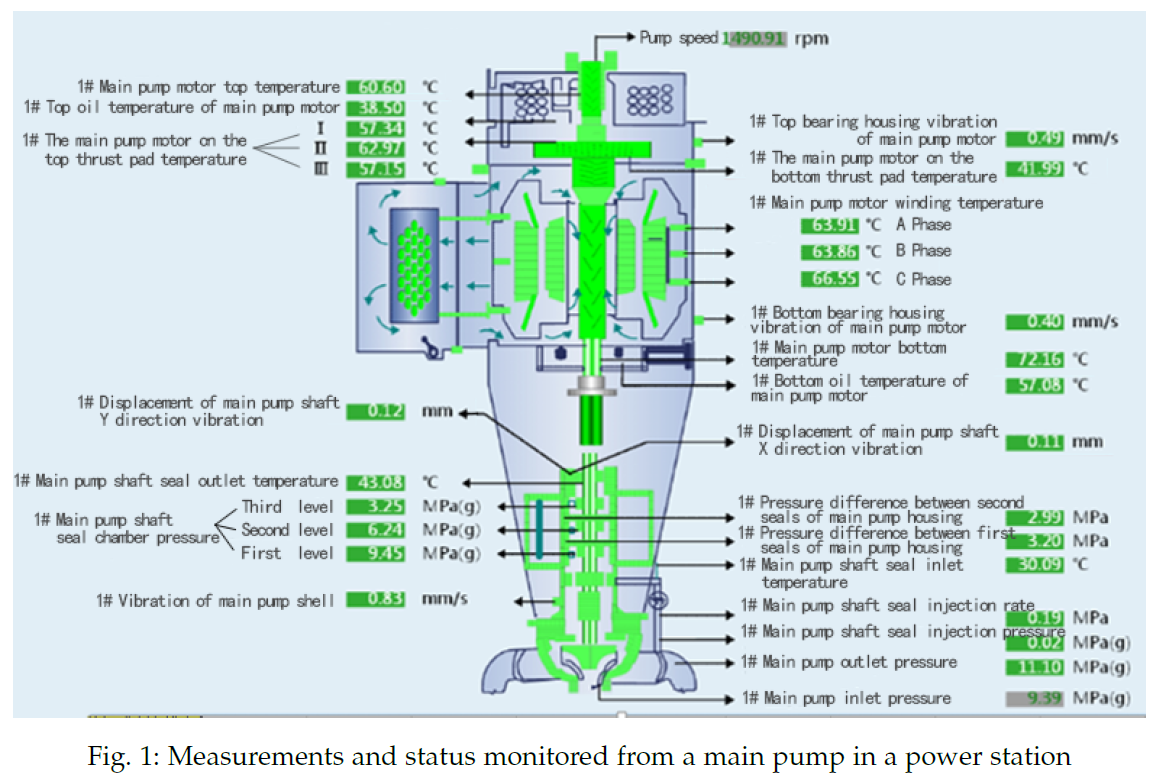
如Fig. 1所示,这是发电厂内部一个核心冷却泵的截面及传感器布局示意图。在这个关键设备上密密麻麻地部署了33个不同类型的传感器,用以24小时记录电机顶部温度、轴承箱振动、密封腔压力等一系列关键参数。实际处理这些由33个传感器产生的多维时间序列数据时,研究人员总结出了以下几个核心特征与挑战:
(1)随着传感器数量的增加,逐一处理所有时间序列会带来极高的数据流和计算负荷。
(2)受环境干扰或传感器自身偶发故障的影响,原始数据中夹杂着大量的随机噪声。
(3)不同位置的传感器之间往往存在不同程度的关联,产生了大量重复的冗余信息。
(4)设备在停机前或修复后,其异常状态往往会持续一段时间,这要求预测模型必须具备记录“长期记忆”的能力。
传统的数学时序预测模型(如 ARIMA)虽然能够处理非平稳数据,受结构限制影响,很难长时间记住长周期的复杂演变状态。为此,研究团队引入了在处理时序序列方面表现优异的LSTM深度学习模型。为了全面应对上述挑战,论文中设计了一套包含数据预处理、特征工程、模型搭建与参数优化的完整工作流:

Fig. 2 展示了该方法的整体架构图。原始序列文件首先进入数据预处理层进行清洗和规范化;接着通过相关性分析提炼核心特征并送入LSTM输入层;随后在嵌入层进行序列转换,最终通过隐藏层和输出层输出预测结果并进行系统评估。在这套流水线中,几个关键步骤对提高预测精度起到了决定性的作用:

(1)原始数据中的异常值会严重干扰模型的训练。如 Fig. 3(左图)所示,研究人员首先利用 K-最近邻(KNN)聚类算法精确定位并剔除了偏离正常范围的异常噪点。随后是数据的规范化。传统的全局规范化方法很难处理跨越不同量级和单位的传感器数据。因此,论文提出了一种窗口规范化(Window Normalization)方法,如 Fig. 3(右图)所示,将长时序分割为长度为L的若干局部片段,在每个窗口内部独立利用最大值和最小值将数据缩放到[0, 1],有效避免传感器更换或单位不同带来的局部尺度偏差。

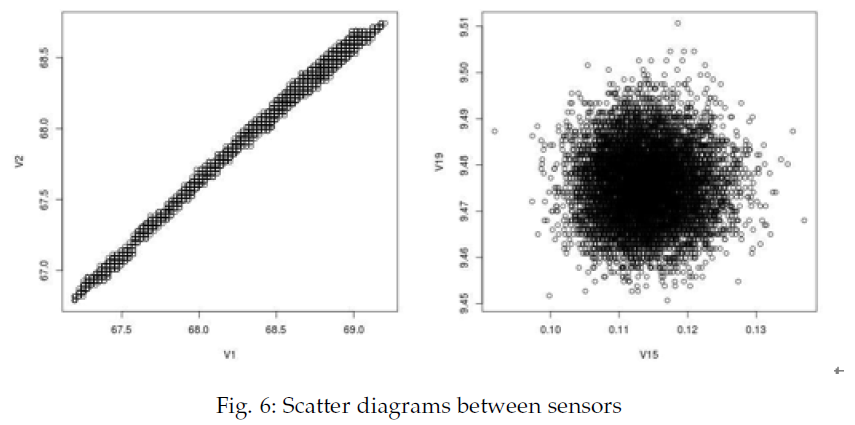
(2)为了解决33个传感器带来的数据冗余问题,研究团队对所有传感器进行了相关性矩阵分析。如Fig. 5的矩阵图所示,不同传感器之间的关联性强弱一目了然(颜色越深代表相关性越强)。Fig. 6 则进一步通过散点图展示了这种规律:位于大水泵同一位置、同类型的温度传感器之间(如传感器1、2、3)表现出了极强的线性正相关关系(Fig. 6 左图);而互不干扰的传感器(如19和15)其散点分布则呈现出毫无规律的二维高斯噪声形态(Fig. 6 右图)。基于这一分析,研究人员将33组传感器大致归为4个主类别,并将强相关序列进行了合并。不仅大幅降低了输入数据的维度和计算复杂度,还保留了传感器内部的本质交互模式。

在传统的LSTM网络基础上,该方法增加了一个嵌入层(Embedding Layer,如图Fig. 4所示),将单维的长序列映射转换成多个固定长度的短向量序列,作为隐藏层的输入,使模型能够更稳定地收敛。此外,由于深度学习模型的超参数(如神经元数量、每批训练大小、迭代次数)很难手动调至最佳,论文引入了正交试验设计(OED)方法。通过正交,模型仅用了4次代表性试验就锁定了最优的超参数组合(5个神经元、批大小为50、迭代5000次),在最低的测试成本下找出了预测误差最小的模型配置。
研究团队将这套优化后的LSTM模型投入到了发电厂冷却泵整整3个月的实际运行历史数据中进行测试。结果表明,LSTM 预测网络表现出了良好的稳定性和可靠性:


Fig. 7 展示了前11个强相关温度传感器的预测效果,图中的初始数据(蓝色)、训练结果(绿色)和预测出的未来结果(红色)几乎完全重合,各点的均方根误差(RMSE)普遍保持在 0.005左右的极低水平。Fig. 8证实,面对曲线形态各异的弱相关传感器(如 13、16、17、32号),该模型依然能给出满意的预测答案。不过如Fig. 8中的12号传感器所示,面对极其不规则的设备振动频率数据时,模型的预测误差会相对放大(RMSE达到0.078),说明高度不规则的数据预测依然是一项挑战。
研究团队将最终结果与经典的ARIMA预测模型进行了正面的对比:

Fig. 9直观对比了28号和25号传感器在两种模型下的预测表现。LSTM模型下,两条曲线的误差(RMSE)仅为0.004和0.010,切换到传统的ARIMA模型后,其预测误差分别飙升到了0.06和0.17。对于12号振动传感器,ARIMA的误差更是高达0.202,远不如LSTM的 0.078。
作者简介:张卫山,中国石油大学(华东)计算机科学与技术学院教授、博士生导师,人工智能系系主任。长期从事联邦学习、区块链、可信人工智能与大数据智能处理研究。
ORCID:0000-0001-9800-1068
DOI:10.1109/ACCESS.2018.2825538











