



机房里修一个坏节点,最怕把跨机架带宽挤爆
 2026-05-26
2026-05-26
 188
188

提到纠删码存储,第一反应都是“它比三副本省空间”。但到了真实数据中心里,麻烦往往在“节点坏了以后,修的时候会不会把网络堵住”。尤其是跨机架带宽,本来就比机架内带宽紧张得多。论文里给出的说法是:这种跨机架链路经常是过度超卖的,最差时每个节点能分到的跨机架带宽可能只有机架内带宽的五分之一到二十分之一。也就是说,真正贵的不是“修复”,是“跨机架搬数据”这一步。
作者没有笼统地追求“总修复流量更低”,而是把问题改写成:如果一个存储节点坏了,能不能少穿越机架去拿数据?答案是可以。作者提出的办法叫 Double Regenerating Codes,简称 DRC。即不再把修复看成“一步到位地从别的机架直接把数据拉回来”,而是拆成两段:先在每个机架内部把数据整理一下,再把整理好的结果跨机架发出来。
转成大白话有点像:传统修法像是总部要补一份材料,于是让每个分部都把原始资料各寄一大包过来;DRC 更像每个分部先在自己办公室里把材料压缩、汇总,只把最需要的一小份发到总部。这样做的目标是优先减少最贵的那段跨机架传输。论文坦白承认,这种做法未必让“机架内加机架间”的总修复流量更低,但它愿意拿更充裕的机架内带宽,去换更稀缺的跨机架带宽。
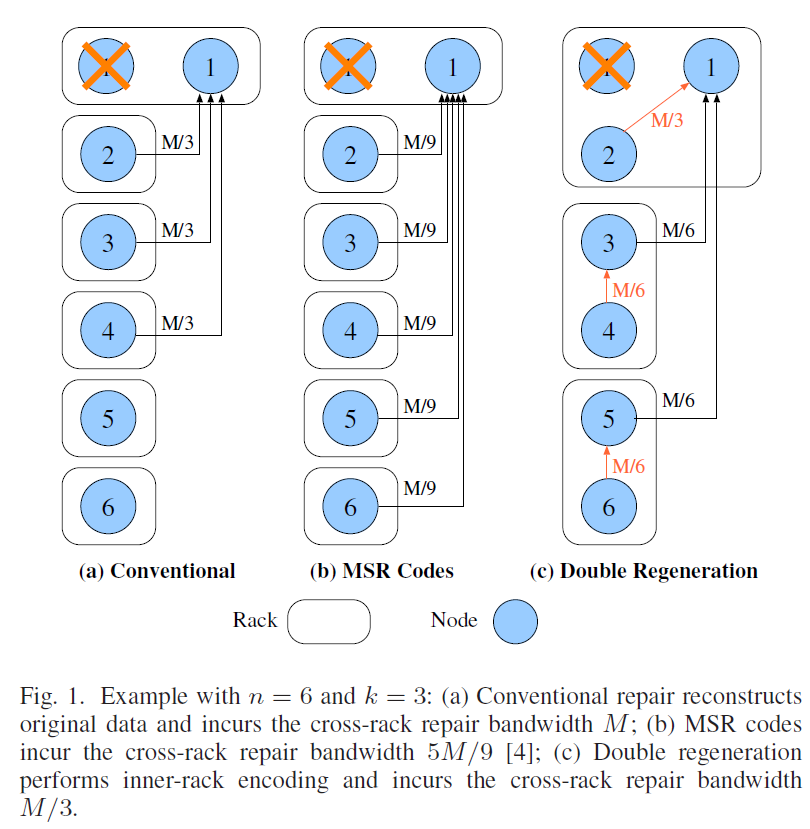
图 1回答了同样修一个坏节点,传统修法、MSR 和 DRC 分别要搬多少跨机架数据。传统修法的跨机架修复带宽是整个原始数据大小 M;MSR 码把它压到 5 M/9;而 DRC 在同一个 n=6、k=3 的例子里,进一步压到 M/3。论文说得很清楚:和 MSR 相比,相当于又少了 40% 的跨机架流量。这一张图已经说明 DRC 的核心价值了,它明确瞄准了数据中心最容易堵的那段网络。
![]()
这篇论文把“理论上到底能省到哪里”也算出来了。作者用信息流图去分析单节点修复,最后在引理 2 里给出一个跨机架修复带宽下界:β ≥ M / k · 1 / (r - floor(kr/n))。说的是:在分层数据中心里,既想保持 MDS 性质(任意 k 个节点仍能恢复原数据),又想尽量少走跨机架带宽,那么你至少得付出这么多。后面作者进一步证明,DRC 这个构造可以碰到这个下界。换句话说,这篇论文在说:按这套模型看,跨机架这一项基本已经压到头了。
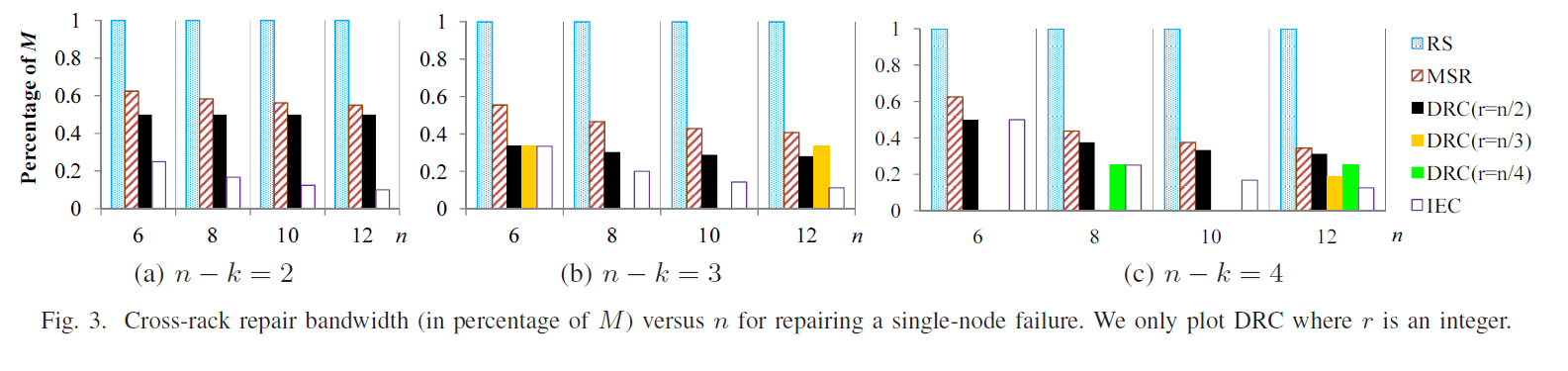
图 3 把结论从“一个例子”扩展成“整类参数”。它回答的问题是:当节点数 n、容错冗余 n-k 和机架数 r 变化时,DRC 相对 Reed-Solomon 和 MSR 还能不能持续占优。在考察的参数范围里,DRC 的跨机架修复带宽始终低于 MSR,最高能低到 45.5%,例子是 n=12、k=8、r=4。说明 DRC 不是只在一个特例里好看,在一整批现实上常见的参数设置里对跨机架修复都更友好。
这篇研究没有把 DRC 写成“神方案”:第一,图 1(c) 那种设计只能容忍一次机架故障,不像前面对比方案那样能容忍更多机架级失效。作者对此的解释是:真实系统里节点故障比整机架故障常见得多,所以这种交换在很多场景下是合理的。第二,DRC 虽然把跨机架修复带宽降下来了,但机架内带宽加跨机架带宽的总和未必更小。比如图 1 的例子里,DRC 的总和是 M,而 MSR 是 5M/9。也就是说,DRC 并不是在所有意义上都更省,而是在“最贵的那一段带宽”上更省。
这篇论文重新定义了“修复最优”到底指什么。过去很多讨论默认所有链路大致同价,所以只要总修复带宽低就行;但在机架式数据中心里,链路不是同价的,跨机架明显更贵。DRC 的研究深度在于没有继续沿着“所有流量一视同仁”的老路走,而是把数据中心的分层拓扑直接写进模型里,围绕真实的成本函数做下界分析和代码构造。
作者简介:胡燏翀,华中科技大学计算机科学与技术学院教授、博士生导师。主要研究分布式存储系统与容错编码技术,聚焦数据中心环境下的高效数据修复与系统可靠性优化。
DOI:10.1109/ISIT.2016.7541298











