



胡亮教授相关成果介绍④:用户-会话上下文推荐:在效率与多样性之间做平衡 Diversifying Personalized Recommendation with User-session Conte
 2026-04-15
2026-04-15
 10322
10322
作者简介
胡亮,同济大学计算机科学与技术学院教授、博导,毕业于上海交通大学与悉尼科技大学,研究方向涵盖人工智能、推荐系统、机器学习与数据科学,入选上海海外高层次人才,获国家自然科学基金优秀青年科学基金项目(海外)支持。
一、研究背景
推荐系统长期偏向给用户推荐“与历史行为相似”的物品,这会带来准确但单调的结果。会话推荐试图利用用户当前会话中的上下文缓解这一问题,但很多已有方法默认会话内部是严格有序序列,并且忽视了用户个体差异。作者认为,真实场景中的会话往往是“松散有序”的,例如购物车中多件商品的加入顺序并不一定有强语义,因此需要一种既考虑会话上下文、又能兼顾个性化和在线效率的新方案。
二、论文信息
发表时间/来源 | IJCAI 2017 |
论文标题 | Diversifying Personalized Recommendation with User-session Context |
作者 | Liang Hu, Longbing Cao, Shoujin Wang, Guandong Xu, Jian Cao, Zhiping Gu |
关键词 | 会话推荐、多样性、个性化、SWIWO、在线推荐 |
三、核心发现
核心发现 论文提出 Session-based Wide-In-Wide-Out Networks(SWIWO),用浅层宽输入-宽输出网络建模“用户-会话上下文”到候选物品的条件概率。与 GRU4Rec 等深层序列模型相比,SWIWO 不强依赖严格序列假设,同时计算更轻量,更适合大规模在线推荐场景。 |
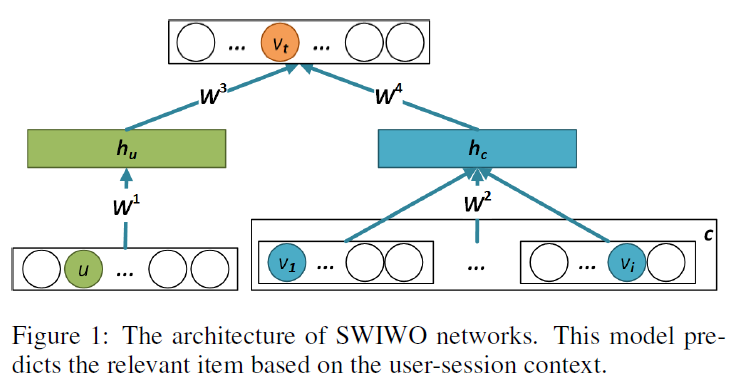
图示:论文原文中的 SWIWO 用户-会话上下文建模结构图
四、研究内容解读
1. 这项研究要回答什么问题?
这项研究首先要回答的是:如何在不牺牲实时性的前提下,让推荐结果既更贴合当前会话,又不过度重复用户历史上已看过、已买过的相似物品?作者把问题重新定义为:给定用户与当前会话上下文,预测哪些物品与该上下文“最相关”,而不只是“最相似”。
2. 研究团队发现了什么?
在模型层面,SWIWO 同时接收两类输入:一类是用户向量,另一类是会话中已出现物品的上下文向量。这种设计借鉴了词向量模型的思想,把会话中的物品看成上下文,把待预测物品看成输出目标,但又额外融入用户表示,从而形成真正的个性化会话建模。
3. 他们是如何证明的?
论文强调,这一结构的优势不只在于更快,还在于它不强迫模型学习“上一件商品到下一件商品”的刚性转移,而是直接学习“整个会话上下文到候选物品”的相关性。这使得模型更适合购物、套餐搭配等弱序列但强共现的场景,也更容易生成多样化推荐结果。
五、关键机制与功能验证
从验证结果看,SWIWO 在真实电商数据集上显著优于 FPMC、PRME 和 GRU4Rec 等方法,REC@10 与 REC@20 均有明显提升。论文还引入 DIV@K 与融合准确率和多样性的 F1@K 评价,说明该方法不仅命中率更高,也确实能产生更丰富的推荐列表。这意味着 SWIWO 的价值不只是效率优化,而是在“个性化准确性”和“推荐多样性”之间给出了更实际的平衡方案。
六、总结与意义
这篇论文的意义在于,它把会话推荐从“深层序列建模”扩展到“上下文相关性建模”,并证明浅层结构在大规模在线场景中同样可以取得更优效果。对于强调部署效率、页面丰富度和用户体验的业务场景,这种思路具有很强的工程参考价值。
DOI:10.24963/ijcai.2017/258











