



减少人工智能的碳足迹
 2020-04-28
2020-04-28
 7283
7283
人工智能已经成为某些道德关注的焦点,但它也存在一些重大的可持续性问题。
去年6月,马萨诸塞州大学阿默斯特分校的研究人员发布了一份惊人的报告,估计训练和搜索某种神经网络体系结构所需的电量涉及约626,000磅的二氧化碳排放量。这相当于包括制造在内的美国普通汽车使用寿命内排放量的近五倍。
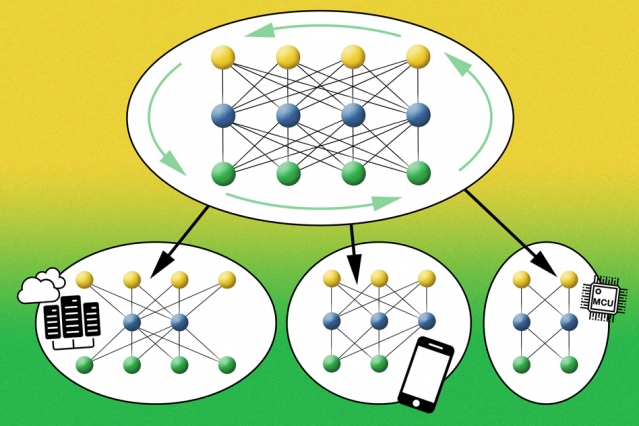
这个问题在模型部署阶段变得更加严重,在该阶段,需要在不同的硬件平台上部署深度神经网络,每个硬件平台具有不同的属性和计算资源。
麻省理工学院的研究人员开发了一种新的自动化AI系统,用于训练和运行某些神经网络。结果表明,通过以某些关键方式提高系统的计算效率,系统可以减少所涉及的碳排放量,在某些情况下,可以降低到低三位数。
研究人员的系统被称为“ 千篇一律的网络”,它训练一个大型神经网络,其中包括许多不同大小的预训练子网络,这些子网络可以针对各种硬件平台进行定制而无需重新训练。这极大地减少了为新平台训练每个专门的神经网络通常所需的能量,而新的平台可能包括数十亿个物联网(IoT)设备。他们使用该系统训练计算机视觉模型,估计与当今最先进的神经体系结构搜索方法相比,该过程需要大约1 / 1,300的碳排放量,同时将推理时间减少了1.5-2.6倍。
“目标是建立更小,更绿色的神经网络,”电气工程和计算机科学系的助理教授宋寒说。“到目前为止,搜索有效的神经网络架构具有巨大的碳足迹。但是,通过这些新方法,我们将足迹减少了几个数量级。”
这项工作是在Satori上进行的,Satori是IBM捐赠给MIT的高效计算集群,它能够每秒执行2次万亿次计算。该论文将于下周在国际学习代表大会上发表。与Han一同参加的还有EECS,MIT-IBM Watson AI Lab和上海交通大学的四名本科生和研究生。
建立一个“万能的”网络
研究人员基于最新的AI进步AutoML(用于自动机器学习)构建了该系统,从而消除了手动网络设计。神经网络会自动搜索大量的设计空间,以寻找适合于特定硬件平台的网络体系结构。但是仍然存在培训效率问题:必须选择每种模型,然后从头开始对其平台体系结构进行培训。
“我们如何针对如此广泛的设备(从10美元的物联网设备到600美元的智能手机)有效地训练所有这些网络?鉴于物联网设备的多样性,神经架构搜索的计算成本将激增。
研究人员发明了一种AutoML系统,该系统仅训练一个大型的“一次全部”(OFA)网络作为“母”网络,嵌套了从母网络中稀疏激活的大量子网络。OFA与所有子网共享所有已学习的权重-这意味着它们实质上是经过预先训练的。因此,每个子网可以在推理时独立运行而无需重新训练。
该团队训练了一个OFA卷积神经网络(CNN)-通常用于图像处理任务-具有通用的体系结构,包括不同数量的层和“神经元”,不同的滤镜尺寸以及不同的输入图像分辨率。在给定特定平台的情况下,系统将OFA用作搜索空间,以根据与平台的功率和速度限制相关的准确性和延迟权衡,找到最佳的子网。例如,对于物联网设备,系统将找到一个较小的子网。对于智能手机,它将选择更大的子网,但根据各个电池的寿命和计算资源,其子网结构会有所不同。OFA将模型训练与体系结构搜索分离开来,并将一次性训练成本分布在许多推理硬件平台和资源约束上。
这依赖于“渐进式收缩”算法,该算法有效地训练了OFA网络以同时支持所有子网。首先以最大的规模训练整个网络,然后逐渐缩小网络的大小,以包括较小的子网。较小的子网在大型子网的帮助下进行了培训,以共同成长。最后,所有大小不同的子网均受支持,从而可以根据平台的功率和速度限制进行快速专业化。添加新设备时,它以零培训成本支持许多硬件设备。 研究人员发现,一个OFA总共可以包含10亿多位数(即1后面是19个零)的体系结构设置,可能涵盖了所有需要的平台。但是训练OFA并进行搜索最终比花费数小时训练每个平台的每个神经网络的效率更高。而且,OFA不会影响准确性或推理效率。相反,它在移动设备上提供了最新的ImageNet准确性。而且,与最新的行业领先的CNN模型相比,研究人员称OFA可以提供1.5-2.6倍的加速比,并且精度更高。 韩说:“这是一项突破性技术。” “如果我们想在消费类设备上运行强大的AI,我们必须弄清楚如何将AI缩小到最小尺寸。”
“该模型非常紧凑。看到OFA能够继续推动边缘设备上高效深度学习的边界,我感到非常兴奋。”麻省理工学院-IBM Watson AI实验室研究员,该论文的合著者Chuang Gan说。
IBM研究员,麻省理工学院-IBM Watson AI实验室成员John Cohn表示:“如果要继续保持AI的快速发展,我们需要减少对环境的影响。” “开发使AI模型更小,更高效的方法的好处在于,这些模型可能还会表现更好。”











