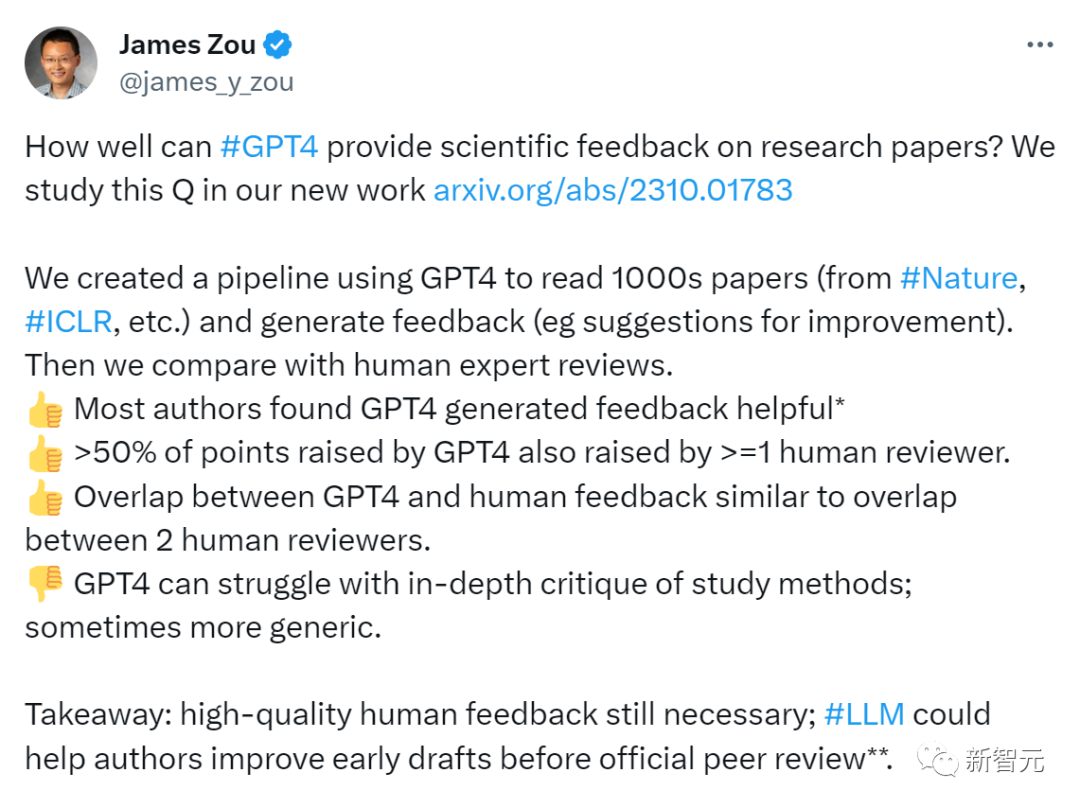
最近,来自斯坦福大学等机构的研究者把3,096篇Nature系列论文和1,709篇ICLR等顶会文章丢给了GPT-4,让它生成评审意见、修改建议,然后和人类审稿人给出的意见相比较。论文地址:https://arxiv.org/abs/2310.01783结果,GPT-4不仅完美胜任了这项工作,甚至比人类做得还好!
它给出的意见中,超50%和至少一名人类审稿人一致。另有超过82.4%的作者表示,GPT-4给出的意见相当有帮助,而且大多数用户打算再次使用LLM反馈系统。论文作者James Zou总结道:我们仍然需要高质量的人工反馈,但LLM可以帮助作者在正式的同行评审之前,改进自己的论文初稿。以下是对同一篇ICLR论文的LLM评论和人类评论,可以看出,LLM的眼光很毒辣,评论很一针见血。比较是有缺陷的。尤其是GNN方法的标签一致性和中心一致性损失都没有考虑到。更公平的比较应该是使用两种损失都考虑到的GNN方法。
论文缺乏与现有方法的彻底的比较。虽然作者对于一些方法比较了基线,但还需要更全面的比较。
恕我直言,理论的证明太琐碎了。最终结论是如果相似度合适,预测的动作就是准确的。由于模型正在学习正确的相似度,也就相当于说模型h如果经过良好的训练,输出就是正确的。这是显然的事。
作者应该提供更多理论分析,来比较信息传递和一致性约束之间的联系,这样能让读者更易于理解。
在研究的可复现性上,人类审稿员希望论文能够提供代码,好让其他读者也能复现实验。GPT-4对此也给出了相同意见:「作者应该提供有关实验设置的更多详细信息,来确保研究的可复现性。」
这项研究让我们知道,LLM确实可以用作改论文神器了!版权声明:文章来源新智元,分享只为学术交流,如涉及侵权问题请联系我们,我们将及时修改或删除。




 2023-10-12
2023-10-12
 41897
41897